
Rust製CLIツールmonolithでnoteの記事を簡単に保存する
monolithとはどのようなツールか
本記事では Rust 製 CLI ツール monolith を使ってnote の記事を一括保存する方法を紹介します。
monolith は、CSS、JS、画像を含む Web ページを1つの HTML ファイルとして保存するRust製のCLIツールです。
Rust をインストールしている場合、cargo コマンドで導入できます。
$ cargo install monolithまた、Homebrew でもインストール可能です。
$ brew install monolithコマンド自体はとてもシンプルで、URL と出力先を指定すれば HTML としてダウンロードできます。
$ monolith https://lyrics.github.io/db/P/Portishead/Dummy/Roads/ -o portishead-roads-lyrics.htmlnoteの記事の保存にmonolithを使う意義
monolith を知ってからユースケースを考えていたのですが、note の記事の一括保存が手軽にできることに気づき、膝を打ちました。
monolith を使うと URL だけで HTML をダウンロードできるため、Puppeteer や Selenium といったヘッドレスブラウザでスクレイピングをするコードを書く必要はありません。
或いは、「note 記事 保存」で検索すると数多くヒットする手法である「それぞれの記事にブラウザでアクセスして、ブラウザの機能を使って PDF にする」という手法も取らずに済みます。
上記の手法と異なり、monolith を使う場合は記事の URL さえあれば記事を保存できるのでとても簡単です。以下はコマンドの例です。
$ monolith https://note.com/foo -o foo.html
$ monolith https://note.com/bar -o bar.html
...保存する記事が少ないならコマンドを1つずつ実行すれば良いでしょう。
しかし、記事数が多い場合、URL を収集するのは骨が折れます。このため、今回は note の API を使って、シェルスクリプトで特定のユーザーの記事を全部取得します。
全記事取得をするスクリプトを紹介する前に、まずは monolith でできること紹介するため、ある記事を試しにダウンロードしてみます。
実際の記事とmonolithでダウンロードした記事を比較する
今回は、LayerX の福島さんの記事を取得します(福島さんの記事はこれからの社会を考えるに当たりとても勉強になります)。
「withコロナの時代と、経済活動のデジタル化」という記事をダウンロードしてみます。
# 13371870 は記事 ID
$ monolith https://note.com/fukkyy/n/n026e8908f5cd -o 13371870.html以下は、ブラウザで表示した note の記事とダウンロードした HTML のスクリーンショットを掲載しています。
「withコロナの時代と、経済活動のデジタル化」(note.com)
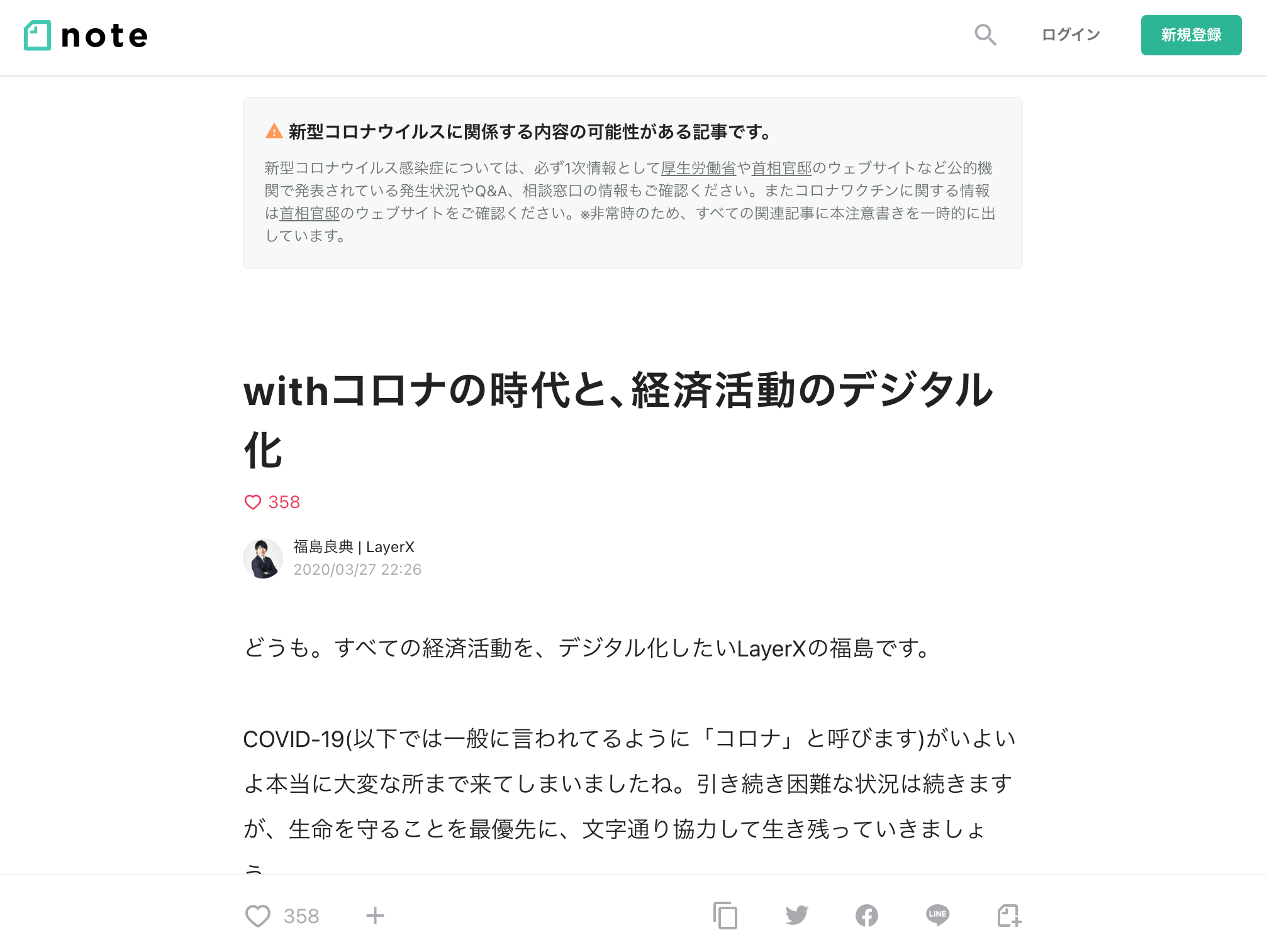
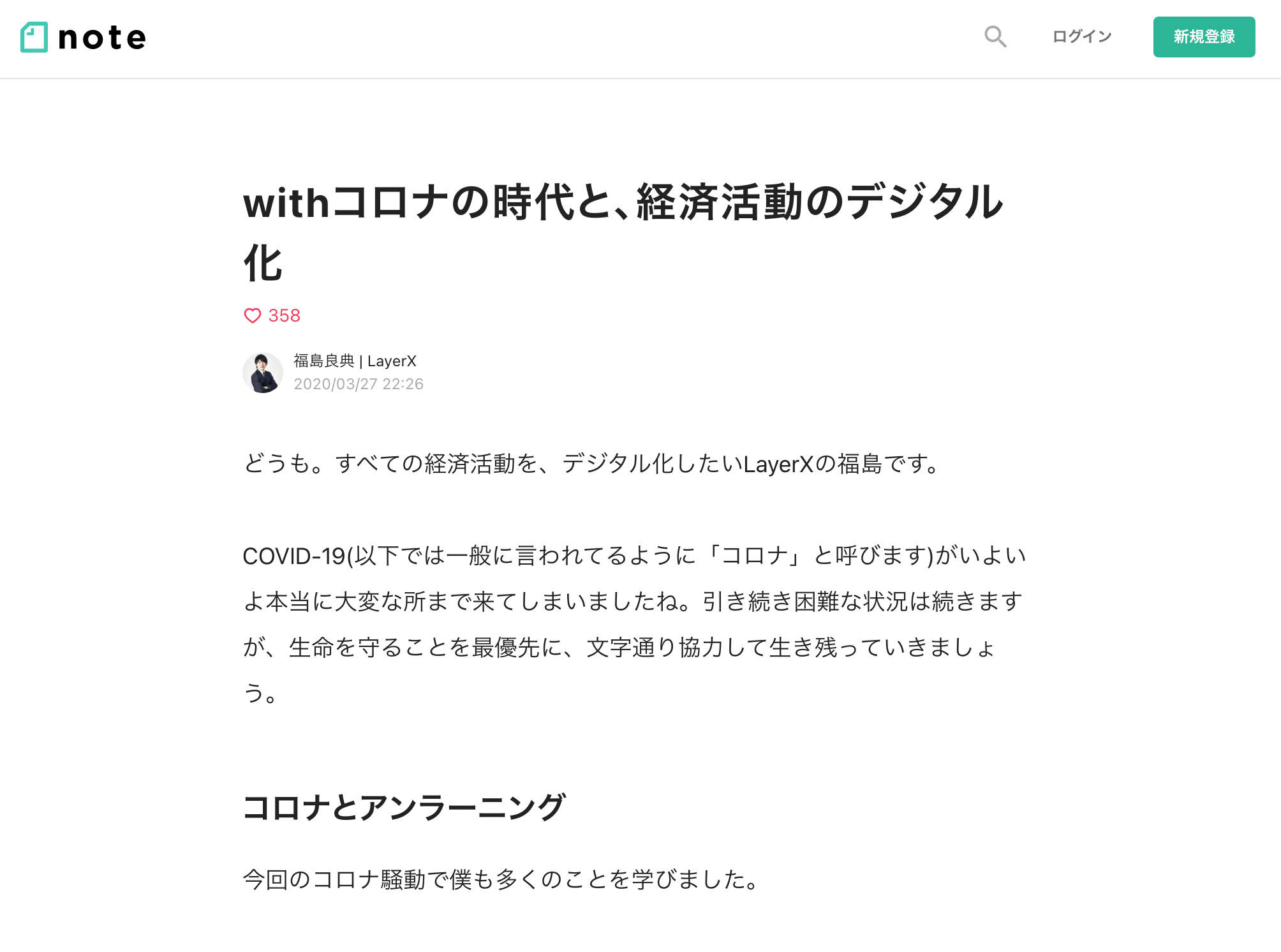
後者のリンクをクリックすると間違って note.com にアクセスしたと錯覚するかもしれませんが、URL を見ると本サイト上の HTML であることがわかります。
実際に比較するとほとんど同じであることが分かります。差分としては以下の項目が monolith でダウンロードした方には存在しない程度です。
- コロナウィルスに関する記述であることを示す警告
- 記事タイトルを表示する header
- 各種ボタンが並ぶ footer
- 同じクリエイターの人気記事
- おすすめの記事

記事の本文を読むだけなら気にならない程度の違いだね
noteのAPIを使って特定ユーザーの全ての記事URLを取得する
では、note の API を使って福島さんの全記事を取得します。API のエンドポイントの URL と返り値は以下の記事を参考にしました。
「【2020年12月版】noteの非公式APIを使ってユーザーの”全記事データ”を取得してみる※pythonコード有り」
福島さんのユーザー名はfukkyyなのでこの値を利用します。
#!/bin/bash
# ユーザー名
NAME=fukkyy
API="https://note.com/api/v2/creators/${NAME}/contents?kind=note"
TOTAL_COUNT=$(curl -s $API | jq ".data.totalCount")
# 記事は6件ずつ取得できるため6で割る
END=$(( $TOTAL_COUNT / 6 + 1 ))
echo "${NAME}氏の記事を取得します"
# $END が小数を含む場合、seq の終端は $END を超えない最大の整数
for i in $(seq 1 $END); do
JSON=$(curl -s "${API}&page=$i")
IDS=($(echo $JSON | jq '.data.contents[].id'))
URLS=($(echo $JSON | jq -r '.data.contents[].noteUrl'))
IDS_COUNT=$(( ${#IDS[@]} - 1 ))
for j in $(seq 0 $IDS_COUNT); do
ID=${IDS[$j]}
URL=${URLS[$j]}
# ホストが COMEMO の場合、クエリを付与する
if [[ $URL == *comemo.nikkei.com* ]]; then
URL="${URL}?gs=0"
fi
mkdir -p "note/${NAME}"
echo "ID: ${ID}"
monolith $URL -s -o "note/${NAME}/${ID}.html"
done
done
echo "end"記事は JSON 形式で6件ずつ取得できます。loop 内で paging をして全ての記事の ID と URL を取得します。
ホストがnote.comではなくcomemo.nikkei.comの場合、gsというクエリを付与しないと HTML を取得できなかったため条件分岐で対応しています。
このスクリプトを実行すると、note/fukkyyディレクトリに HTML ファイルが作成されます。
.
└── note
└── fukkyy
├── 10147393.html
├── 10456869.html
├── 11562526.html
...
└── 9753513.html他の方の記事を取得したい場合は、ユーザー名を変更して実行するだけで OK です。
まとめ
monolith を使うと JS、CSS、画像が1つの HTML ファイルにまとまるので整理がとても楽です。
購入済みの有料記事を保存するのであれば以下の手順で取得できます。
- curl でログイン session(
_note_session_v5) とともに記事 URL にリクエストを送る - 結果をローカルにファイルとして保存する(ex.
foo.html) $ cat foo.html | monolith -b https://note.com/foo - > result.htmlを実行する
また、HTML を 画像 に変換したい場合は、Puppeteer を使えば10行程度のコードで実現できます。
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('file:///Users/name/note/fukkyy/8911395.html');
await page.screenshot({ path: '8911395.png', fullPage: true});
await browser.close();
})();便利な CLI ツール monolith の紹介でした。