「JSON色付け係」という自虐
フロントエンドエンジニアの間では、「私の仕事は JSON に色を付けることです」という有名な自虐ネタがある。 おそらく初出は以下のツイートなのだろう(*1)。ただ、出典はあまり詳しく調べていない。
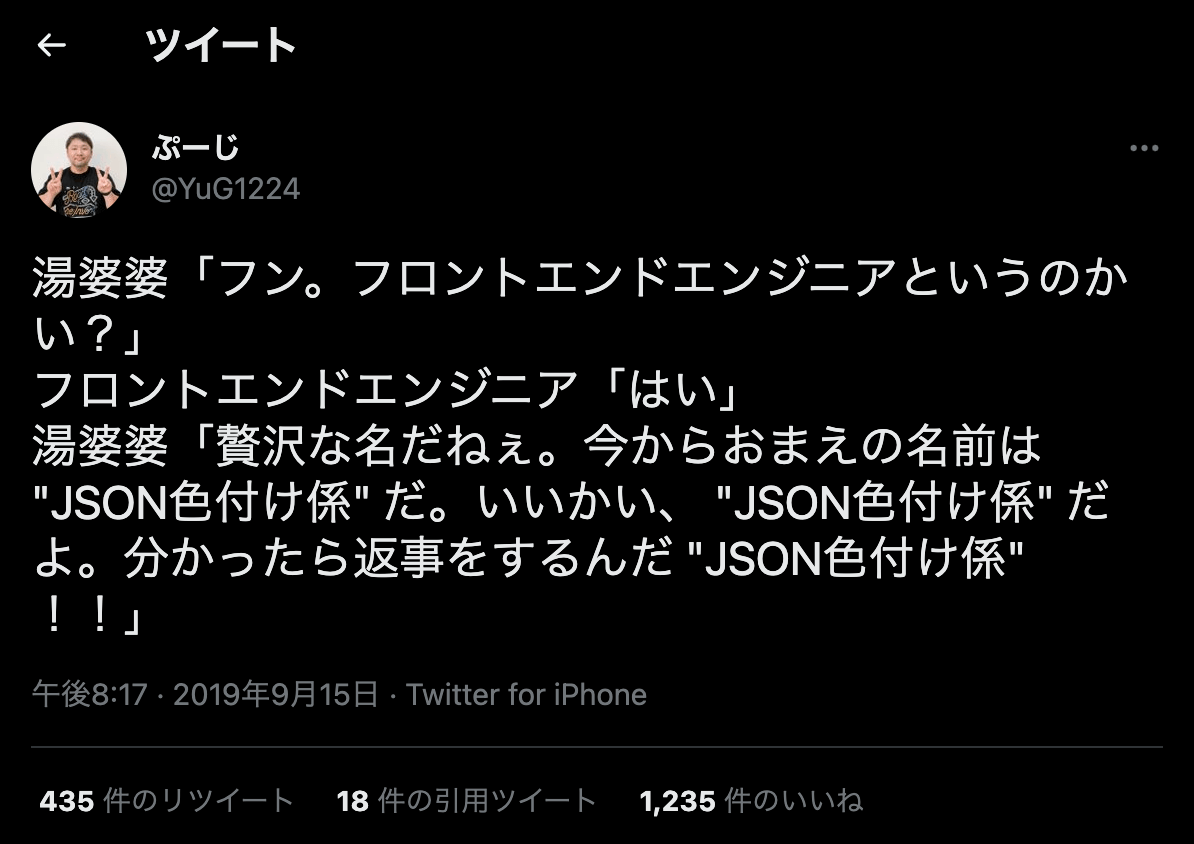
初めてこの言葉を見た時、面白い言い回しだなと思った。確かにフロントエンドの仕事にそういう側面はある。
実際、コンテンツの表示がメインのページで作業すると上記のような気持ちになる。この場合、フロントでやることといえばせいぜい日付の表示形式を適切にフォーマットするくらいだ。結局バックエンドからデータが返ってこないとフロントだけでは何もできないと思うこともある。
もちろん、フロントだけで簡潔する手書き風グラフ作成ツール excalidraw のようなものは別だし、フロントで複雑な状態を扱う部分を書いたり、フォームを使ってユーザー入力を受け付け、入力値を検証するバリデーションをしてからバックエンドに POST リクエストを送るような処理を書いていると、自分は JSON 色付け係だなんて思わない。やっぱりフロントエンドエンジニアは必要なんだなと思う。
ただ、なぜフロントエンドエンジニアは JSON 色付け係と自虐(自己卑下)するのか。
この言葉を知った時には次のように考えた。自分達はインフラやバックエンドのように高度なエンジニアリングをしているわけではなく、API から送られてくる JSON のデータをユーザーに表示しているだけで大したことをしていないという感覚を誰しもが持ったことがあるからだと。
しかし、これでは JSON 色付け係という言葉が指していることを説明しただけで、言葉が使われて受け入れられる背景にまでは辿り着けていないなあと漠然と思っていた。
JSON はシリアライズされた DTO である
そのうち「JSON 色付け係」という言葉は Twitter のタイムラインであまり見なくなった。 しかし、最近ある偶然から「JSON 色付け係」という言葉を使うメンタリティはこれだという洞察を得たので、ここで紹介したい。
その偶然とは、PoEAA本で DTO を調べてみたことである。調べた内容を 「GraphQL と Data Transfer Object は似ている」 という記事にした。そこで DTO は XML にも JSON にもシリアライズできるものだと書いた。
すると、その記事を読んでくれた元同僚が「CQRS を考案した Greg Young 氏が、DTO を介してサーバーとクライアントがやり取りするとドメイン知識は失われてしまうと指摘している」と教えてくれた(*2)。
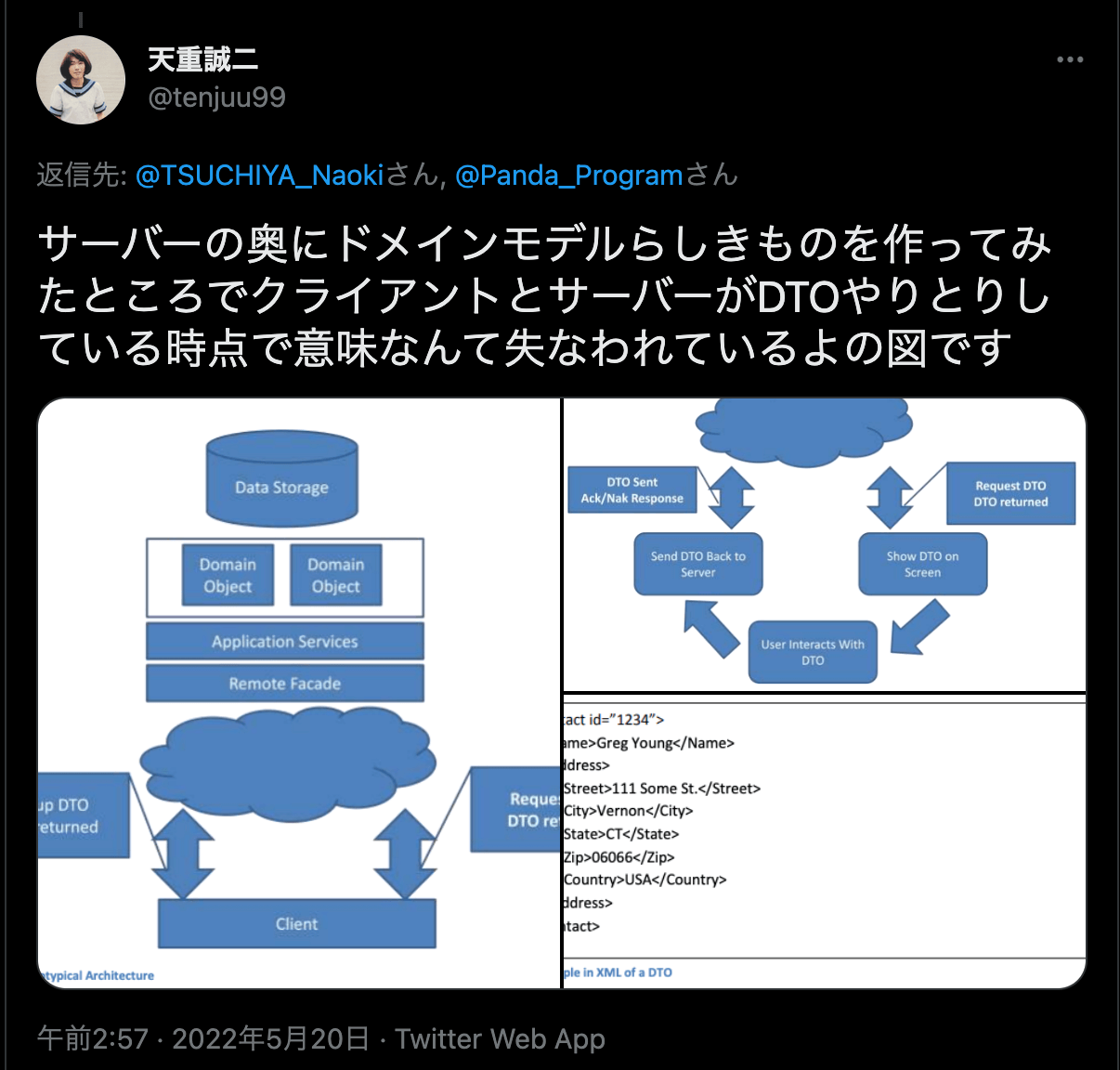
CQRS の文章を読むと確かに以下のように書かれている。抜粋した文章はクライアントから送られてくる DTO をバックエンドで処理する際の指摘だが、Greg Young 氏が考えている課題の内容が伝わってくる箇所だ。
One cannot even create and Anemic Domain Model with this architecture as then all of the business logic would be in services, here the services themselves are really just mapping DTO’s to domain objects, there is no actual business logic in them. In this case a large amount of business logic is not existing in the domain at all, nor in the Application Server, it may exist on the client but more likely it exists on either pieces of paper in a manual or in the heads of the people using the system.
CQRS Documents by Greg Young, p.7
超訳すると以下のようになる。
「クライアントから送られてくる DTO をバックエンドで受け取ってサービスが DTO をドメインオブジェクトに変換するだけだと、ビジネスロジックとドメイン知識がすっかり失われてしまう。ドメイン知識はクライアント側に存在するかもしれないが、それよりも紙のマニュアルやシステムを使う人の頭の中の方にあるのだろう」
つまり、ドメイン知識は DTO からも DTO を送られたバックエンド側からもなくなってしまい、マニュアルやシステム利用者の頭の中にしかないことになってしまうということだ。
ここで想定されているやりとりをコードで表現すると以下のようになる。ブログのシステムで、タイトルだけを編集することを考えてみよう。
まず、編集画面にバックエンドから JSON (DTO)が送られてくる。
{
"title": "SEO的にイケてないタイトル",
"body": "本文..."
}これをクライアントで受け取り、画面からタイトルを編集した後、バックエンドに送られる JSON は以下のようになる。
{
"title": "SEO的に超イケてるタイトル",
"body": "本文..."
}この JSON をサービス層でドメインオブジェクトにマップすると、タイトルを編集したというドメイン知識が失われるだろう。疑似コードで表現すると以下のようになる。
const json = handler(request)
const post = service.map(json)
repository.save(post)これでは送られてくる JSON を保存しているだけだ。タイトルを更新するというドメイン知識は失われている(そして、この課題を解消するために CQRS パターンを使おうという話に繋がる)。
これはフロントのコードも同様だろう。以下のコードにビジネスロジックはどこにもない。
const App = () => {
const { data: post } = useSWR('/api/posts/1', fetcher)
return (<Post post={post} />)
}
type Post = {
title: string
body: string
}
const Post = (post: Post) => {
return <div>
<h1>{post.title}</h1>
<div>{post.body}</div>
</div>
}つまり、DTO からはドメイン知識が失われてしまうというのが Greg Young 氏の指摘だ。 これはフロントからバックエンドに JSON を送る際にも、バックエンドからフロントに JSON を送る際にも同じことが言える。
この指摘が、「JSON 色付け係」という自虐のメンタリティを読み解く最後のピースになった。
JSON からはドメイン知識が抜け落ちている
これらをまとめると以下のようなロジック(三段論法)になる。
- DTO とそれをシリアライズ化した JSON はビジネスロジックを持たないため、ドメイン知識を保持できない。
- (表示がメインのアプリにおいて)フロントエンドは JSON のデータを表示するプレゼンテーションロジック担当である。
- よって、JSON を表示するだけのフロントエンドにはドメイン知識がない。
つまり、ドメイン知識が反映されたビジネスロジックと無縁のコードばかりを書かざるを得なくなった結果、エンジニアなのに大事な何か(ドメイン知識)に関与していないという心情が芽生えた。それこそが自らを「JSON 色付け係」と自虐させたのである。
ちなみに、ここでいう色とは「ドメイン知識とは無縁な、見た目を良くするためのプレゼンテーションロジック」だと理解している。「JSON色付け係」とは、なんとも上手い表現だと改めて思う。
以上が私の推理なのだが、みなさんはどうお考えだろうか。
最後に注意書きを。冒頭で紹介したように、今回はフロントエンドが価値の中心になるアプリやツールは議論の対象外だ。
「私は JSON 色付け係です」とフロントエンジニアが感じるような、データ表示が中心のページ・アプリを話題にしてそのメンタリティを読み解いているので、「全てのフロントエンドのアプリケーションにはドメインロジックがない」と主張しているわけではないので悪しからず。
(*1): https://twitter.com/YuG1224/status/1173194238139363329?s=20&t=j45fvJMEBGZvD2xVSRUn1w
(*2): https://twitter.com/tenjuu99/status/1527347738332975120?s=20&t=22hgo9RU4rEcpiUWnFiF3g







