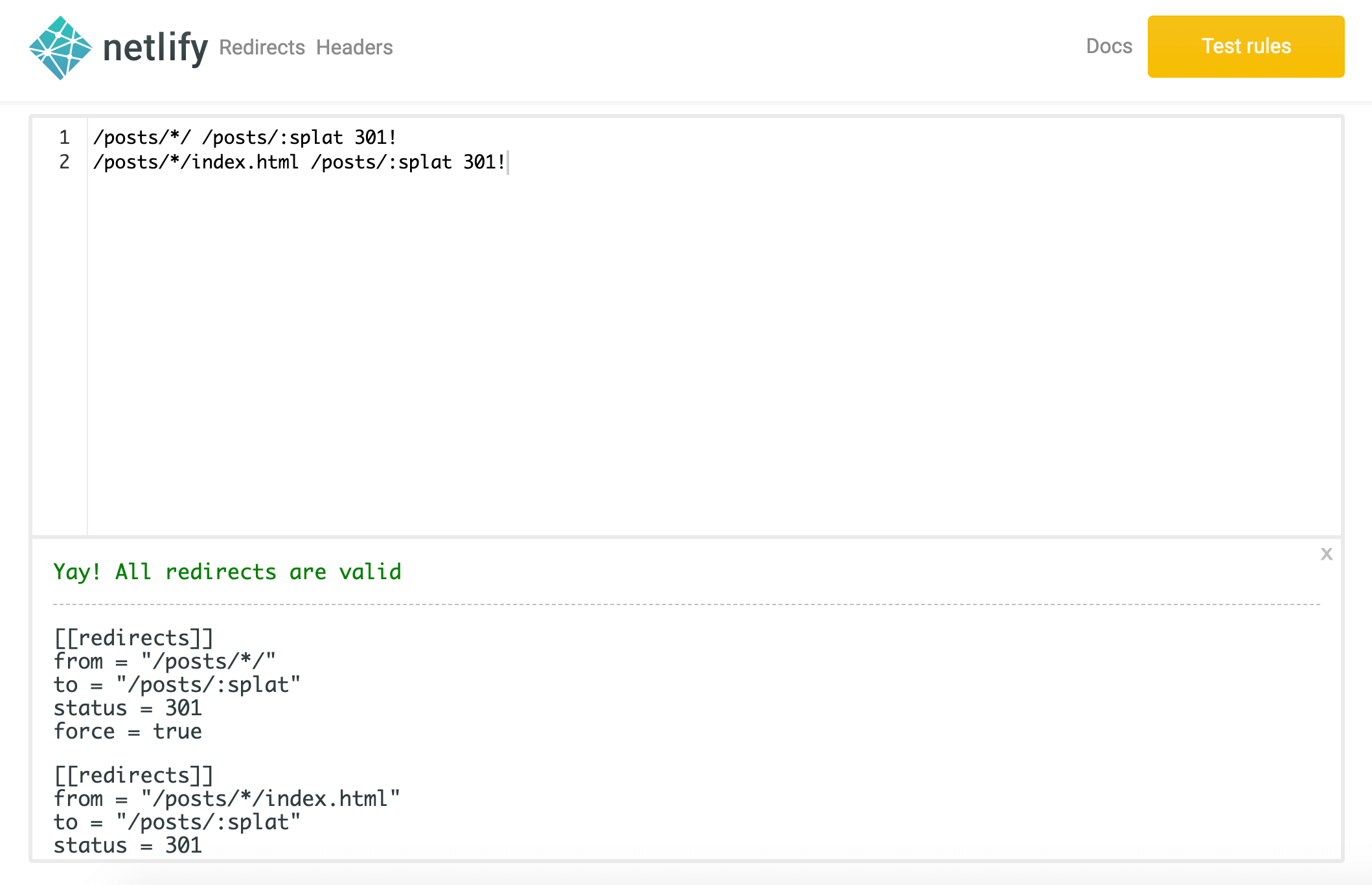
LaravelでTailwind CSSを使いたい
Laravelでサイトのデザインをするにあたり、Tailwind CSSを使いたい方向けに、セットアップの手順を解説します。
Tailwind CSSとは、Bootstrapのようにクラス名を指定するだけでスタイルを当てることができるツールです。デザインがモダンで、Bootstrapより柔軟にカスタマイズできるのが特徴です。
対象のバージョンは以下です。
Laravel 6.2
Tailwind CSS 1.1.2関連記事: Tailwind CSSでCSSが苦手なエンジニアでもイイ感じのサイトが作れることを伝えたい
Tailwind CSSをインストールする
Tailwind CSSをインストールします。
$ npm install tailwindcsspackage.jsonが更新されていれば成功です。
{
// scriptsなど
"dependencies": {
"tailwindcss": "^1.1.2"
}
}tailwind.config.jsを作成する
tailwind.config.jsをプロジェクトに追加します。このファイルが、Tailwind CSSのカスタマイズ性を象徴しています。
$ npx tailwind init初期ではカスタマイズ不要であるため、tailwind.config.jsに下記のコードを追加します。
module.exports = {
theme: {},
variants: {},
plugins: [],
}詳しい使い方は公式ドキュメントをご覧ください。
Tailwind CSSをapp.scssから呼び出す
resources/sass/app.scssに下記の3行を追記するだけでOKです。
@tailwind base;
@tailwind components;
@tailwind utilities;この中にTailwind CSSの本体が入っています。CSSにコンパイルすると、クラス名とCSSのスタイルが出力されます。
laravel-mixにTailwind CSSの設定を書く
laravel-mixとscssを使う場合、webpack.mix.jsに+で記述している行を追加しましょう。
const mix = require('laravel-mix');
+ const tailwindcss = require('tailwindcss');
mix.js('resources/js/app.js', 'public/js')
.sass('resources/sass/app.scss', 'public/css')
+ .options({
+ processCssUrls: false,
+ postCss: [ tailwindcss('./tailwind.config.js') ],
+ });processCssUrlsは、LaravelがCSSをコンパイルする際に、url関数で指定した画像の相対パスをドキュメントルートからのパスに書き換えてくれる最適化をする機能です。
しかし、laravel-mixでTailwind CSSをビルドする場合、このオプションがonになっているとエラーが出てしまうため、processCssUrlsは必ずfalseにしましょう。
全てのオプションについてはlaravel-mixのMix Optionsをご覧ください。
laravel-mixでビルドする
$ npm run devでアセットファイルが開発用にビルドされます。
DONE Compiled successfully in 4372ms 12:50:40 AM
Asset Size Chunks Chunk Names
/css/app.css 855 KiB /js/app [emitted] /js/app
/js/app.js 591 KiB /js/app [emitted] /js/app本番環境で使う際は、$ npm run prodでjs、cssのファイルサイズを縮小してビルドしましょう。
出力されたapp.cssを確認する
public/css/app.cssを確認してみましょう。
/*! normalize.css v8.0.1 | MIT License | github.com/necolas/normalize.css */
/* Document
========================================================================== */
/**
* 1. Correct the line height in all browsers.
* 2. Prevent adjustments of font size after orientation changes in iOS.
*/
html {
line-height: 1.15; /* 1 */
-webkit-text-size-adjust: 100%; /* 2 */
}
/* Sections
========================================================================== */
/**
* Remove the margin in all browsers.
*/
body {
margin: 0;
}
/**
* Render the `main` element consistently in IE.
*/
main {
display: block;
}
// 以下続く成功です。
Tailwind CSSを使ってオシャレにラクにスタイリングしていきましょう。