
弁護士ドットコムライブラリーのフロントエンドのアーキテクチャ(Next.js + TypeScript)
弁護士ドットコムライブラリーのフロントエンドのアーキテクチャを紹介します
この記事は弁護士ドットコム Advent Calendar 2020、2日目の記事です。2020年12月に執筆された記事です。
私は弁護士ドットコムライブラリーというサービスを開発しています。これは法律書籍をネットで読める弁護士向けのサブスクリプションサービスです。

フロントエンドの採用技術はNext.js + TypeScriptで、要件定義から設計、実装は私が担当し、現在も運用しています。
この記事では、2020年5月にリリースしてから半年間、Next.jsで上記サービスを運用した知見の中から、フロントエンドでのアーキテクチャについてご紹介します。
弁護士ドットコムライブラリーの特徴は以下の通りです。
- 画面数は10画面ほどの中規模アプリケーション(OOUIの考え方を取り入れたら画面数が減りました)
- 基本的にバックエンドから渡されるデータを整形・表示するRead要件がメイン
- バックエンドは認証、書籍検索(Elastic Search)、課金(Stripe)のマイクロサービス
- ECS上でNodeコンテナとして運用しているため、VercelやNetlifyは利用していない
- CSSについては、デザイナーさんがHTML+CSSを記述してくれるのでCSS Moduleを利用。Atomic Designは採用していない
なお、Storeの構成については、Read要件がメインのサービスでありシンプルなため、この記事では特に触れません。
サービスの利用については、現在、弁護士ドットコムに登録している弁護士の方、または弁護士事務所の事務所単位で利用する方のみ登録可能です。ただ、書籍の検索は誰でも可能なので、動かしてみたい方はトップページから検索ワードを入力してみてください。
技術スタックは以下の通りです。
- フレームワーク: Next.js(React) + TypeScript
- 状態管理: useContext(Reduxを導入する予定)
- データフェッチ: Next.js組み込みのfetch、 SWR
- CSS: CSS Modules(SCSS)
- テストフレームワーク: Jest、 @testing-library/react-hooks
- CDN: Akamai
- CI: GitLab CI
- インフラ: ECS、ECR、RDS(MySQL)
- 監視: Datadog
- その他: ESLint・Stylelint・Storybook、Renovate、Docker Compose、Stripe普段はDiscordを使いながら、ペアプログラミングで開発しています。
レイヤードアーキテクチャを採用
結論から記述すると、フロントエンドでレイヤードアーキテクチャを採用しました。
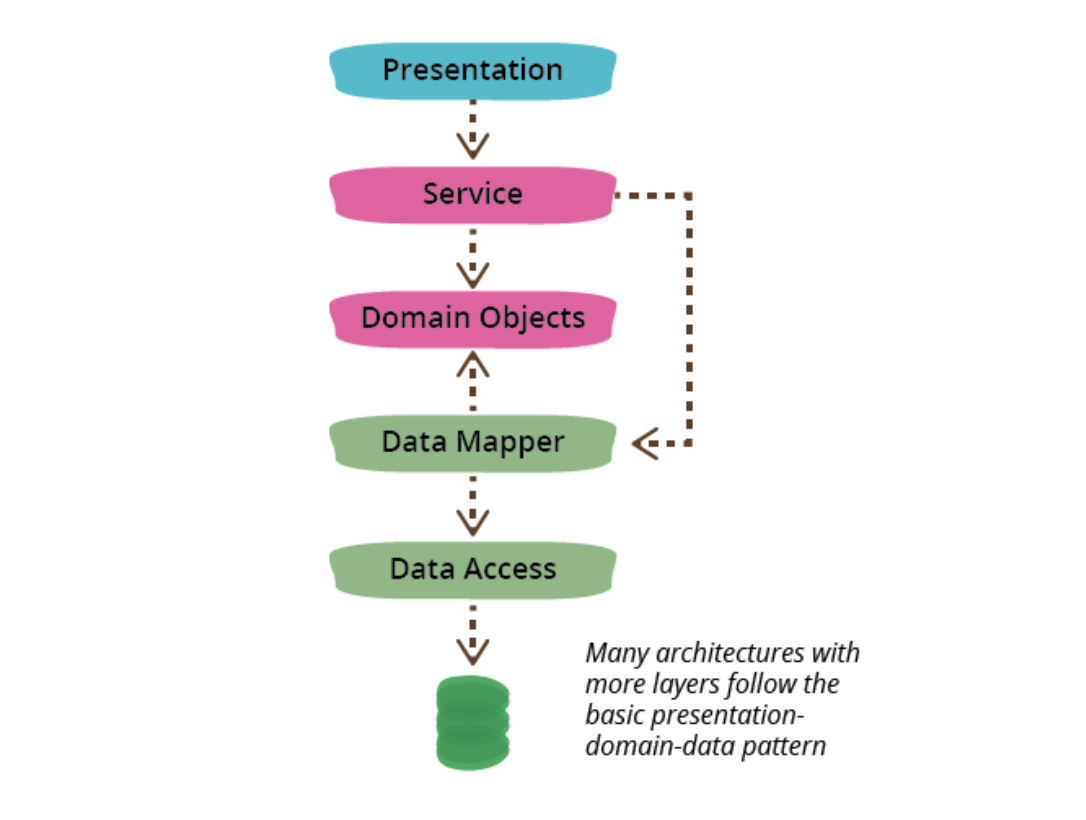
(図はマーティン・ファウラーのブログ記事「PresentationDomainDataLayering」より)
「PresentationDomainDataLayering」とボブおじさんのクリーンアーキテクチャを参考にレイヤードアーキテクチャを採用し、各レイヤーがクリーンになるように設計しています。
昨今、フロントエンドでクリーンアーキテクチャを適用する試みが見られます。しかし、そもそもクリーンアーキテクチャはWebを外部のI/Oであると定義しており、デスクトップやCLIでも動作する、MVC2ではないアプリケーションを想定しています。
弁護士ドットコムライブラリーはWebアプリケーションであるため、クリーンアーキテクチャを適用しましたとは言わないものの、クリーンアーキテクチャのエッセンスを抽出した「クリーンなアーキテクチャ」を目指して設計しました。
このアーキテクチャの特徴は、以下のようなものです。
- レイヤーごとの責務が明確であること
- モジュールの依存の方向が制御できていること
- モジュールがテスタブルであること(本記事執筆時点で、Unit Testのテストカバレッジは85%です)
- 外部のものはアダプターとして使い、アプリケーション内に依存をばら撒かないこと
これらの特徴を備えたアプリケーションは、メンテナンス性に優れており、仕様の追加や変更に強く、コードの処理が追いやすくなります。
ディレクトリ構成
上記の特徴を実現するために、ディレクトリ構成は次のようにしています。
app
├── pages # next.jsのページコンポーネント。各tsxのファイル名がURLのpathに対応している。
├── public # 静的ファイルを置く場所。faviconとか、サイトのロゴなど
│ └── images # サイト内で使用する画像
└──src
├── assets # pages、componentsで利用する共通のSCSS
├── components # ReactのFunction Component、コンポーネント単位のSCSS
├── hooks # コンポーネント間で共通のReact Hooks
├── interactors # Network層。HTTPを介して外部と通信するクラスを置いている
├── lib # Adapter層。moment.jsやGoogle Analyticsのライブラリなどを呼び出している
└── type # アプリケーション内で共通の型を置いている
├── API # RESTful APIのエンドポイントから返却されるJSONの型
└── domain # アプリケーション内で利用する型Next.jsを採用しているため、ルートディレクトリにあるpagesディレクトリのファイルがルーティングに対応しています。ファイルシステムに基づいたルーティングは、素のHTMLをサーバーで配信するのと同じですね。
components内には、React Componentを記述しています。この中は、export用のindex.ts、FooコンポーネントのFooComponent.tsx、コンポーネント内で利用するSCSS(style.modules.scss)、Storybook用のコンポーネント(index.stories.tsx)、プレゼンテーションロジックを記述するpresenter.ts(後述)を配置しています。
また、interactorsというディレクトリはあまり見かけないと思います。この役割はfetcherとmapperです。つまり、APIのレスポンスデータであるJSONをJavaScriptのオブジェクトに変換し、TypeScriptでドメインの型にマッピングするための処理を記述しています。このレイヤーにより、APIの変更による影響を最小限に抑えることができます。こちらは次の章で説明します。
なお、ユーザーのリクエストからレスポンスまで、データフローは以下のような流れです。
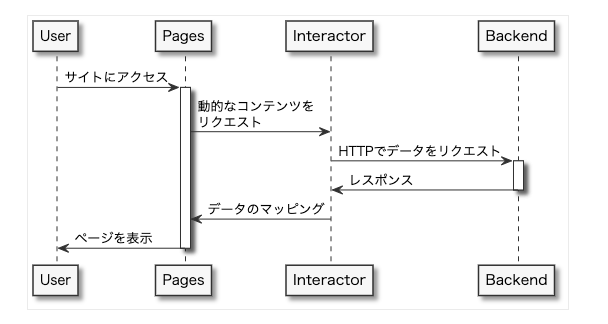
InteractorとMapper(データアクセス層)
Interactorの役割
Interactorはバックエンドからデータを取得するレイヤーです。interactorsディレクトリの中身は以下の通りです。
interactors
├── BaseInteractor.ts # fetchをラップした、get, post, put, deleteメソッドを備えたクラス。
├── Books # 書籍データを持つElastic Searchサーバーへのリクエストを担当
│ ├── Book
│ │ ├── BookInteractor.ts
│ │ └── BookMapper.ts
│ └── Search
│ ├── SearchInteractor.ts
│ └── SearchMapper.ts
├── Payment # Stripeサーバー(決済)へのリクエストを担当
│ ├── Card
│ │ └── CardInteractor.ts
│ ├── Customer
│ │ └── CustomerInteractor.ts
│ └── Subscription
│ ├── SubscriptionInteractor.ts
│ └── SubscriptionMapper.ts
└── Session # Sessionサーバー(ユーザー認証情報)へのリクエストを担当
├── SessionInteractor.ts
└── SessionMapper.tsBook、Payment、Sessionの3種類のInteractorは、それぞれ書籍の検索、課金、ログインセッションサーバーの各エンドポイントに対応しています。
この3種類のInteractorクラスにBaseInteractorを注入し、HTTPメソッドに応じた通信をするようにしています。
例えば、書籍サーバーからIDに応じて書籍データを取得するコードを掲載します。
export default class BookInteractor {
// ClientInterfaceはget/post/put/deleteメソッドを持つインターフェースです
private readonly interactor: ClientInterface
constructor() {
// BaseInteractorを注入
this.interactor = BaseInteractor.createBookInteractor()
}
findById = async (id?: string): Promise<Book | null> => {
if (typeof id === 'undefined') {
return null
}
// IDに応じた書籍データを取得する
const res = await this.interactor.get(`${BOOK_BIBLIOGRAPHIES_PATH}/${id}`)
try {
const body: BookBody = await res.json()
// 次で解説しています
return BookMapper.bibliographyBodyToBook(body)
} catch (e) {
// 例外をnullで表現していますが、アンチパターンだと思うため要リファクタリングです😅
// なお、SWRでこのクラスを利用すると、try/catchの記述は省略できます
return null
}
}
}エンドポイントごとにInteractor(fetcher)を用意しているため、エンドポイントが増えればInteractorを追加すれば仕様追加に対する変更が完了します(Open Closed Principle)。
或いは、「書籍を全件取得する」という仕様が追加された場合、BookInteractorにfindAllメソッドを記述するだけでOKです(Single Responsibility Principle)。
なお、クエリストリングが必要な場合、interactor.getの第二引数に渡します。
Mapperの役割と特徴
Mapperの役割は、バックエンドが返却する値にフロントのアプリケーションを依存させないことです。Mapperの特徴は、Interactorのメソッドと1対1対応していることです。
その内容は、エンドポイントから返されるJSONをドメインの型にマッピングするためのクラスです。
export default class BookMapper {
// BookBodyはレスポンスの型、Bookがアプリケーション内で利用する型です
static bibliographyBodyToBook = (result: BookBody): Book => ({
id: result.content_id,
title: result.title.main,
subTitle: result.title.sub,
authors: result.authors || [],
publisher: result.publisher,
publishedAt: result.release_date,
tableOfContents: result.toc,
thumbnailUrl: result.thumbnail_url,
abstract: result.abstract,
url: result.url,
})
}Mapperというレイヤーを設けておくことで、バックエンドから返却される値が変わった場合出会っても、このMapperを変更するだけで済みます。このため、アプリケーション内部の変更の影響を最小限に留められます。
なお、返却されるJSONがとてもシンプルな場合は、Mapperを書かずにInteractorの中でドメインの型にマッピングすることもあります。
InteractorをReactで利用する際は、useEffect内でInteractorを呼び出すことでレスポンスデータを扱います。
type Props = { id?: string }
const Book: React.FC<Props> = (props) => {
const [book, setBook] = useState<BookType | null>({})
useEffect(() => {
async(() => {
setBook(await new BookInteractor().findById(props.id))
})()
}, [props.id])
if (book === null) {
return <Error message={"書籍取得に失敗しました"} />
}
return <h1>title: {book.title}</div>
}このInteractorはSWRでも活用できます。
type Props = { id?: string }
const Book: React.FC<Props> = (props) => {
const { data: book, error } = useSWR<Book>(
`${BOOK_BIBLIOGRAPHIES_PATH}/${props.id}`,
() => new BookInteractor().findById(props.id)
)
if (!book) {
return <Loading />
}
if (error) {
return <Error message={"書籍取得に失敗しました"} />
}
return <h1>title: {book.title}</div>
}ReactコンポーネントとPresenter層(プレゼンテーション層)
弁護士ドットコムライブラリーはバックエンドからのデータ表示がメインのアプリケーションであるため、Interactorから渡された値を表示するためのロジックを格納するPresenter層を用意します。バックエンドに例えるとMVVMのViewModel層に相当します。
Presenter層を紹介する前に、まずはクリーンなReactコンポーネントの書き方をご紹介します。
クリーンなReactコンポーネントの書き方
Greetingコンポーネントを例にReactコンポーネントの書き方を紹介します。すると、src/components/greetingは下記のような構成になります。
src/components/greeting
├── __tests__
│ ├─ useGreeting.test.ts
│ └─ presenter.test.ts
├── index.ts
├── index.stories.ts
├── Greeting.tsx
├── presenter.ts
├── useGreeting.ts
└── style.module.css今回は、hooksと、そのテストの記述は省略します。なお、ドラッグ&ドロップなどの複雑なUIの操作は存在しないため、@testing-library/reactによるコンポーネントテストは導入していません。
CypressによるE2Eテストは導入したいと思っていますが、現在はJestと@testing-library/react-hooksによるUnit Testのみ記述しています(Unit Testのコードカバレッジは85%)。
また、Reactコンポーネントの書き方は、@takepepeさんの「経年劣化に耐える ReactComponent の書き方」を参考にしています。
この記事の意義は、Vue.jsのSFC(Single File Component)の書き方をReactに導入したことです。これにより、View(JSX)をComponentに、データ表示用のロジックをContainerに記述し、責務を分離できます。詳しい説明は記事をご覧ください。
import React, { memo } from 'react'
import css from './style.module.scss'
type ContainerProps = {
target?: string
}
type Props = Required<ContainerProps>
// デザイナーさんはComponentのJSXを記述すれば良い
// StorybookではComponentのみをimportする
export const Component: React.FC<Props> = (props) => (
<h1 className={css['greeting']}>
Welcome to, <span className={css['greeting__target']}>{props.target}</span>
</h1>
)
// フロントエンドエンジニアが書く
// propsをComponentで表示するデータ形式に書き換える
const Container: React.FC<ContainerProps> = (props) => {
const target = props.target || 'world'
return <Component target={target} />
}
// memo化はComponent、ContainerのどちらでもOK
export default memo(Container)コンポーネントのmemo化については、ContainerでもComponentでもどちらでも適切な方をReact.memoでラップしましょう。
また、Storybookのコンポーネントは以下のように記述しています。
Storybookのコンポーネントはプレゼンテーションであるため、importするのはComponentです。
Containerに記述するlocal stateやデータの変換処理は不要です。Storybook上でコンポーネントのstateを操作せずとも、Container(ViewModel)の処理の結果としてComponentに渡されるデータを複数用意すれば十分です。
以下は、Storybook v6 + TypeScriptの記述方法です。
import { Meta, Story } from '@storybook/react'
import { Component as Greeting, Props } from './Greeting'
export default {
title: 'components/Greeting',
component: Greeting,
argTypes: {
target: { control: 'text' },
},
} as Meta<Props>
const Template: Story<Props> = ({ ...args }) => <Greeting {...args} />
export const World = Template.bind({})
World.args = {
target: 'World'
}
export const Next = Template.bind({})
Next.args = {
target: 'Next.js'
}Presenterの役割
さて、Presenterについて紹介します。presenter.tsは、Container内でのロジックをテスト可能にするための関数を記述するファイルであり、コンポーネントと1対1に対応するロジックを記述します。
「コンポーネントに閉じるロジックなら、Containerに直接関数を書いてもいいのでは?」という意見もありました。しかし、クリーンなアーキテクチャを設計する観点からロジックをコンポーネントから切り出しています。理由は以下の通りです。
- Container内のロジックをテスト可能にするため
- コンポーネント内にはPresentational Componentとロジックを記述するContainerしか配置しないため
- ファイルの見通しが悪くなるため、functionや子コンポーネントは、例え小さいものでも同一ファイルに記述しない
- Reactコンポーネントのファイルは1ファイル100行以下にしておきたいためただし、全ての処理をpresenter.tsに記述するわけではありません。三項演算子やStringをNumberに変換する処理など、テストをせずともバグの原因になる不安のないものは、Container内に直接記述しています。
実際のPresenterは以下のように記述しています。
下記は、ヘッダーに配置している検索欄の表示/非表示をページごとに切り替えるロジックです。なお、各ページのパスは定数に切り出しています。
const canShowSearchInput = (
pathname: string,
keyword: string | undefined,
hitCount: number | null
): boolean => {
switch (pathname) {
case SITE_SEARCH_PATH:
// 検索結果が0件の場合は表示しない
if (hitCount === 0) {
return false
}
// キーワードが存在しないときは表示しない
return !!keyword
case SITE_BOOKS_ID_PATH:
// 書籍の個別ページなら、必ず表示する
return true
default:
return false
}
}
export default canShowSearchInputこのようなロジックは要件が複雑になると記述量が増えるためContainerコンポーネントの中に書きたくありません。また、stateを使ったロジックでもないので、あえてコンポーネント内に書く必要もありません。
(検索欄はトップページでは非表示ですが、検索ページでは表示しています)
検索欄の表示、非表示なのでComponent(View)はbooleanさえ渡してもらえればよく、presenter.tsに切り出すのが適切なパターンといえるでしょう。あとはContainerで処理を呼び出すだけです。
import Logo from '~/src/components/logo'
import Presenter from './presenter'
type ContainerProps = {
pathname: string
keyword?: string
hitCount: number | null
}
type Props = {
canShowSearchInput: boolean
}
export const Component: React.FC<Props> = (props) => (
<nav>
<Logo />
{props.canShowSearchInput && <SearchInput />}
</nav>
)
const Container: React.FC<ContainerProps> = (props) => {
const canShowSearchInput = Presenter.canShowSearchInput(
props.pathname,
props.keyword,
props.hitCount,
)
return <Component canShowSearchInput={canShowSearchInput} />
}(Headerコンポーネントは説明のため簡略化しています)
Presenterのテストを記述することにより、ユーザーに意図しない形でデータやコンポーネントが表示されているかもしれないという不安がなくなります。
型の依存の方向を制御する(Types)
一般的に、モジュールの依存の方向を整理しなければアプリケーションが複雑になります。TypeScriptでの型定義も同様です。このため、型ファイルをsrc/typesに全て配置するようにしました。
このディレクトリ内の型ファイル自体は外部の何にも依存していないため、src/componentsやpages配下でのみ使います。これにより、Reactコンポーネント内で使う型の依存方向を一方向にでき、依存の方向を制御できます。
ただ、特定のコンポーネントツリーでしか使わない型について、最近はsrc/componentsの各コンポーネントでtypes.tsファイルを作り、そこに書くようにしています。この型ファイルは他のコンポーネントツリーでは使用しません。2箇所以上で同じ型を使う場合、globalなものとみなしてsrc/types配下に切り出します。
また、初期では避けていましたが、今では子コンポーネントのPropsをexportして親コンポーネントで利用することもあります。こちらも、「同一コンポーネントツリー内のみで、子から親へのみimport可能」というルールを設けています。
マーティン・ファウラーのPresentationDomainDataLayeringとの対応
最後に、冒頭で紹介したファウラー氏のPresentation、Service, Domain Objects、Data Mapper、Data Accessと各レイヤーの対応をチェックします。
Presentation
PresentationはReact ComponentのContainerのロジックとPresenterに対応します。
Service, Domain Objects
この層に対応するレイヤーはありません。APIからjsonで取得したデータを表示させるだけであるので、Entitiy同士が相互作用する場面や、Storeから取り出した値を組み合わせて使う場面がないためです。
Data Mapper
APIから取得したJSONをアプリケーション内で使う型に変換する層であるため、InteractorのディレクトリにあるMapperに対応します。なお、Interactorの各メソッドとMapperは1対1で対応している。
Data Access
Data AccessはInteactorに対応しています。Inteactorという名前は同僚の@tenjuu99さんが開発している業務システムのコードを参考にしました。なお、業務システムはNuxt.js + BEAR.Sunday(PHP)で構築されています。
また、バックエンドのAPIはデータベースではありません。このため、Data Access層との対応は疑似的なものです。
半年間運用してみた所感
半年間運用してみた結果、感触はとても良いと思いました。
- Presenter(Container)とComponentを分けるのは、思考がシンプルになる
- 各レイヤーの責務が明確なので、仕様の追加・変更があっても、コードを読む箇所、書き換える箇所が狭い
- 処理を追加する際、何をどこに書くか悩まない
- デザイナーさんとの協業が楽(「CSSをいじるときにComponentだけ見ればいいのでわかりやすい」とのデザイナーさん評)
総じて、Next.js自体がディレクトリ構成までは指定しないフレームワークなので違和感はないです。また、新しいメンバーがジョインしても、MVCで開発した経験があれば容易に理解できると思います。
アーキテクチャを考え、テストを書き、慎重にデプロイした結果、半年間の本番で小さいバグは数個あったものの、中・大規模な障害は1度も発生せず、デプロイの切り戻しは一度もありませんでした。このため、安心して開発できます。
これからリファクタリングをしていきたいこと
以下では、これからのリファクタリング案を記載しています。現行のアプリケーションで特に問題にはなっておらず、またイテレーションの中で消化するタスクとして切り出してはいませんが、更なる品質向上のために必要だと思うことを書き出しています。
- 初期はsrc/componentsにコンポーネントの粒度を気にせず置いていたので、下記のようにコンポーネントを整理する
- pages/sharedで分ける
- pagesはそのページでしか使わないコンポーネント
- sharedは2箇所以上で使う共通コンポーネント
- pages/sharedで分ける
- useContext/useReducerで行っているglobalな状態管理をRedux + reselect + immerに置き換える
- Next.jsのpagesはNext.jsとstoreとの接続層とする。Next Routerもこの層でしか使わないようにする
- Next.jsへの依存を限定するため
これらは、時間を見つけて対応していきたいです。
設計段階の狙いはかなりの部分で達成していますが、まだまだやりたいことはたくさんあります。質問などがあればtwitterまでぜひよろしくお願いします。
最後に、フロントエンドのアプリケーションを構築した経験から、結局アーキテクチャや採用技術はアプリケーションの性質・仕様・要件次第だと考えています。本記事は、write要件の少ない中規模のアプリケーションのアーキテクチャ例として一読いただければ幸いです。本記事での考え方はReactのアプリケーションに留まらず、どこか別のところでも応用できると考えています。
明日、アドベントカレンダー3日目は弁護士ドットコム本部・開発部のTech Lead @kano さんの「Polyfill.io を使って JavaScript の Polyfill を適用する」です!
追記(2022年6月)
少し補足をします。記事を書いてから2年半の時間が経ちました。自分は弁護士ドットコムを2021年4月に退職しており現在の状況はわかりません。
記事内容に今でも通用する箇所もありますが、振り返ると interactor はどうも必要なさそうだと思ったり(クラスまで作る必要なく、fetcher をラップした関数群で良い)、「redux + reselect + immer に置き換えたい」と書いていたり(結局 useReducer + useContext のまま)、型の置き場所も今読むと要検討だと思う内容だったり、内容が古くなっている箇所もあります。
キーをスネークケースからキャメルケースに変更するのも camelcase-keys のようなライブラリに任せれば自前で書かなくて済むし、そもそもこのプロジェクトはバックエンドのスキーマを Open API を使って定義していたので今から考えると fetcher を自動生成できました。
エラーハンドリングは記事内で TODO としていますが、もし今やるなら { data, error, status} の形式で返すように設計すると思います。
この記事は内容に古いところはあるものの、それでもフロントエンドでユニットテストを書いているという実例として価値があると考えています。また、Presenter(Container)と Component に分けるのは、当時ベストだと考えていたものの、実際に他の現場ではあまり見ないですし、自分も個人開発ではもうやっていません。ただ、弁護士ドットコムではデザイナーさん全員が HTML と CSS を書けるため、コンポーネントを修正する際にデザイナーさんからは「最初は React だと聞いて全くわからないなと抵抗感があったが、直すべき箇所が Component だとわかるので修正するのに心理的負担がなくなった」と評判でした。そういった特殊事情もあったことを追記します。
フロントエンドの変化のスピードは早いです。記事の内容を鵜呑みにせず、現在の技術トレンドと世間で定着した技術、読んでくださる方のアプリケーションの要求・仕様を勘案して適宜読み替えて頂けると幸いです。